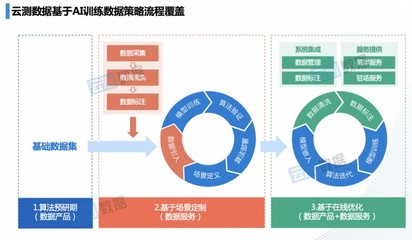
隨著人工智能技術的不斷發展,其在各行各業的落地應用日益深化。在這一過程中,高質量的數據成為驅動AI模型優化與業務創新的關鍵要素。云測數據憑借其專業的數據處理服務,為人工智能業務流程提供了持續、可靠的高價值數據支撐,助力企業實現智能化轉型。
云測數據通過智能化標注工具與專業團隊結合,確保數據標注的準確性與一致性。在圖像識別、語音處理、自然語言理解等領域,云測數據能夠提供多模態、多場景的數據處理方案,滿足不同AI應用對數據的高標準需求。無論是自動駕駛中的道路環境數據,還是醫療AI中的影像數據,云測數據都能通過精細化的標注與清洗,提升數據的可用性與價值。
云測數據注重數據的安全與合規。在數據處理過程中,云測數據嚴格遵守相關法律法規,采用加密傳輸、權限管控等技術手段,保護用戶數據的隱私與安全。同時,通過數據脫敏、匿名化處理等方式,確保數據在合法合規的前提下被高效利用,為企業構建可信賴的數據供應鏈。
云測數據還通過自動化流程與人工審核相結合,提高數據處理效率。在AI模型訓練與迭代過程中,云測數據能夠快速響應客戶需求,提供大規模、高質量的數據集,縮短AI應用的開發周期。通過持續優化數據處理流程,云測數據幫助企業在競爭激烈的市場中保持技術領先地位。
云測數據的服務不僅限于數據標注與處理,還延伸至數據質量評估與優化建議。通過深度分析數據特征與應用場景,云測數據為客戶提供個性化的數據解決方案,助力AI模型在實際業務中發揮最大效能。從數據采集到最終應用,云測數據全程參與,確保每一環節的數據價值得到充分挖掘。
云測數據以其專業、高效、安全的數據處理服務,成為人工智能業務流程中不可或缺的合作伙伴。未來,隨著AI技術的進一步演進,云測數據將繼續深化數據服務能力,為更多行業的智能化升級提供堅實支撐。