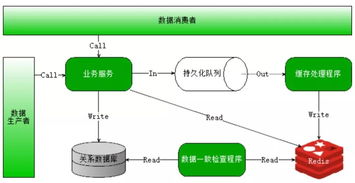
在數字化浪潮席卷全球的今天,傳統制造業的商業模式正經歷著深刻變革。TCL作為中國家電行業的領軍企業,在探索線上線下一體化(O2O)的道路上,其高管單曉鵬所倡導的“以大數據驅動產品買賣成為產品服務”的理念,正引領著企業從單純的產品銷售者向綜合服務提供商的戰略轉型。這一轉型的核心,是將海量的數據處理轉化為精準的服務能力,從而重塑客戶關系與價值鏈條。
一、 從交易到交互:大數據重構用戶連接
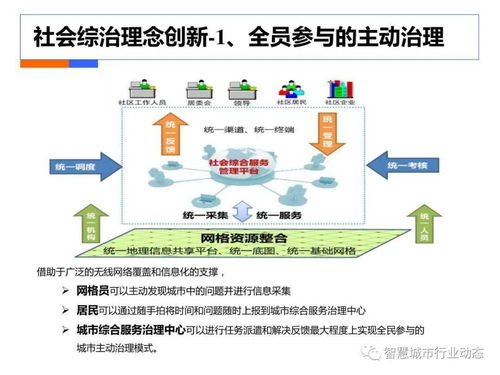
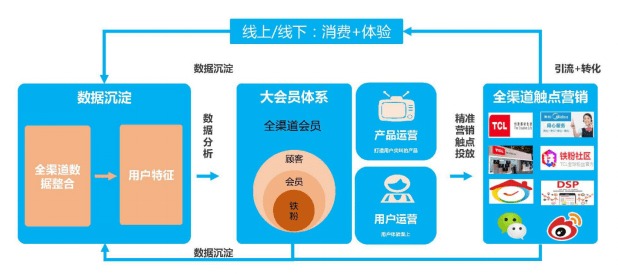
傳統家電銷售往往止步于產品交付,企業與用戶的連接是短暫且薄弱的。TCL O2O模式通過整合線上商城、社交媒體、線下門店及智能產品終端等多維觸點,構建了全渠道的用戶數據池。每一次瀏覽、點擊、購買、安裝、使用乃至售后咨詢,都成為寶貴的數據源。單曉鵬強調,這些數據不再是冰冷的數字,而是理解用戶需求、習慣與潛在痛點的“語言”。通過大數據分析,企業能夠精準描繪用戶畫像,預測產品生命周期內的服務需求,將一次性的“買賣關系”轉化為持續的“服務交互”。例如,通過分析智能電視的開機率、應用使用偏好、觀影時長等數據,TCL可以主動推送個性化的內容推薦、進行耗材預警(如濾網更換),甚至提供基于使用場景的增值服務方案。
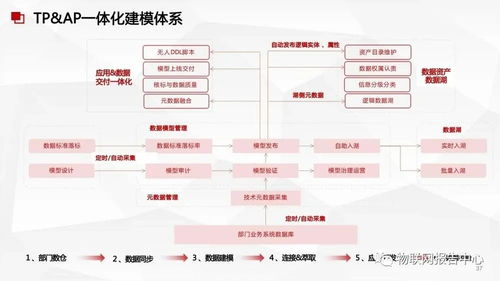
二、 數據處理服務:從后臺支持到前臺價值引擎
“數據處理服務”在此范式中扮演著關鍵角色。它超越了傳統IT部門的支撐功能,演變為直接創造客戶價值、驅動業務創新的核心引擎。這涉及幾個關鍵層面:
- 數據整合與治理:打破線上、線下及各產品線間的數據孤島,建立統一、標準化的數據中臺,確保數據質量與一致性,為深度分析奠定基礎。
- 智能分析與洞察:運用機器學習、預測算法等先進技術,從數據中挖掘規律。例如,分析不同區域、人群的空調使用數據,可以優化產品功能設計(如更適應南方潮濕天氣的除濕模式),或指導區域性營銷和服務資源投放。
- 服務化輸出與場景應用:將數據分析能力封裝成可調用的服務,靈活賦能于各個業務環節。面向消費者,這可能體現為個性化的智能家居方案推薦、能效管理建議;面向內部,則可能是優化供應鏈庫存、預測零部件需求以提升售后響應速度。
單曉鵬推動的正是這樣一種認知轉變:數據處理的最終目的不是生成報表,而是生成可行動的服務指令和創造新服務的機會。
三、 O2O閉環:數據驅動服務落地的現實路徑
O2O模式為“產品即服務”的理念提供了完美的落地場景。線上平臺負責高效引流、數據收集與初步互動,線下龐大的經銷商與服務網絡則承擔起深度體驗、交付、安裝及復雜服務的重任。大數據在其中起到“中樞神經”的作用:
- 服務需求預測與調度:根據產品銷售數據、用戶地理位置和使用數據,提前規劃安裝、維修等服務資源,實現精準預約與快速響應。
- 個性化服務匹配:分析用戶歷史行為,當客戶在線下門店咨詢時,店員可通過系統獲取其線上瀏覽記錄和偏好,提供更具針對性的產品組合與增值服務建議。
- 服務過程優化與體驗提升:服務工程師上門后,其手持終端可顯示該產品的特定使用數據或常見問題提示,助力高效排查。服務完成后的用戶反饋數據又回流至系統,用于優化產品和服務設計。
由此,產品買賣的終點變成了長期服務關系的起點,用戶為“體驗與結果”持續付費的商業模式成為可能。
四、 挑戰與未來展望
這條轉型之路也布滿挑戰。數據安全與用戶隱私保護是必須堅守的紅線;傳統組織架構、考核體系與數據驅動的服務文化需要協同變革;對數據分析人才的渴求也日益迫切。
單曉鵬與TCL O2O的實踐揭示了一個清晰的趨勢:在物聯網與智能時代,產品的硬件價值將逐漸趨于穩定,而基于數據的衍生服務將成為差異化和利潤增長的主要源泉。家電或許將更像一個“服務接入終端”,企業競爭的核心將聚焦于誰能為用戶提供更貼心、更智能、更持續的數據處理服務與生活解決方案。這不僅是一場技術升級,更是一場從“制造產品”到“經營用戶”的深刻商業哲學演變。