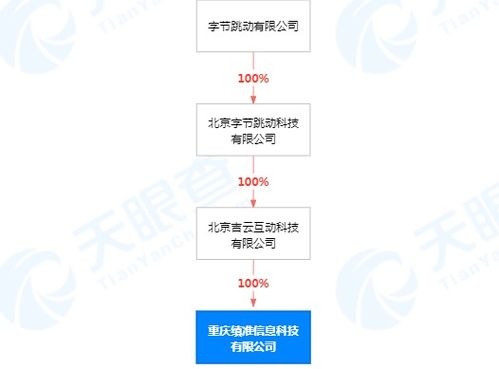
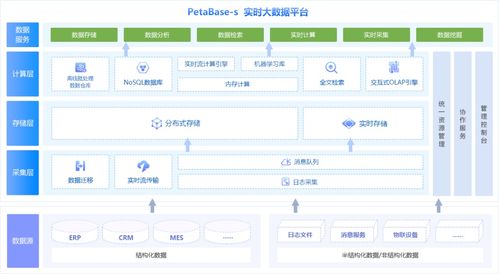
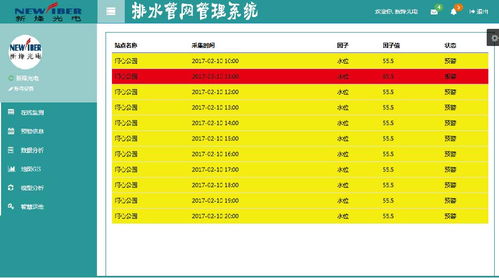
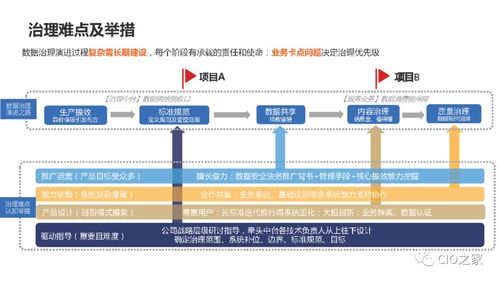
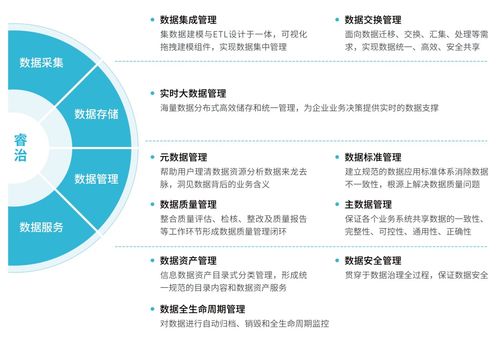
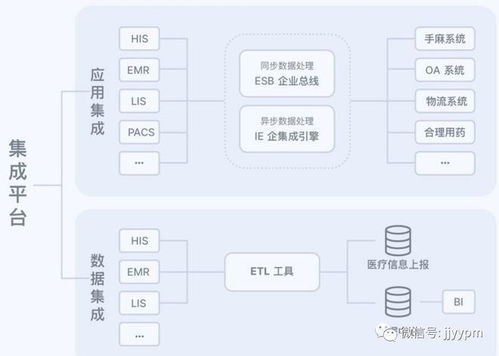
在當今工業4.0時代,大眾工廠的大型計算機中心成為了智能制造的核心樞紐。這些大型計算機以其卓越的計算能力和高吞吐量,承擔著處理工廠海量數據的重任。從生產線傳感器實時采集的運行參數,到供應鏈管理的物流信息,再到質量檢測的影像數據,每天都有數以TB計的數據在這里匯聚、分析與存儲。
在軟件開發層面,基于大型計算機的數據處理能力,工程師們構建了高度定制化的工業軟件生態系統。這些軟件不僅實現了生產流程的自動化控制,還能通過機器學習算法對設備故障進行預測性維護,顯著提升了生產效率和設備利用率。同時,大數據分析平臺能夠深入挖掘歷史生產數據,為工藝優化和產能規劃提供科學依據。
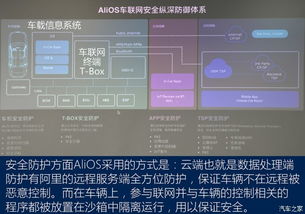
值得注意的是,大型計算機中心的軟件開發遵循嚴格的安全標準和實時性要求。開發團隊采用微服務架構和容器化部署,確保系統的高可用性和可擴展性。通過虛擬化技術,單一物理主機能夠同時運行多個獨立的開發環境,大大提高了資源利用率和開發效率。
隨著5G、物聯網和邊緣計算技術的發展,大眾工廠的大型計算機中心將繼續演進,其軟件開發將更加注重實時數據分析、人工智能集成和跨系統協同,為智能制造注入持續創新的動力。