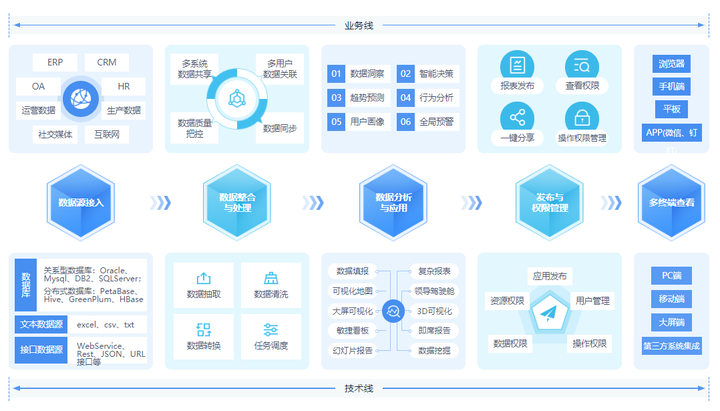
隨著科技的飛速發展,數字化轉型已成為各行各業提升效率、優化資源的關鍵路徑。在下水務領域,數字化轉型不僅有助于改善水資源管理和服務,還面臨著技術、資金和管理等多重挑戰。本文結合行業動態,探討下水務數字化轉型的挑戰、實踐以及能耗管理系統在其中的作用。
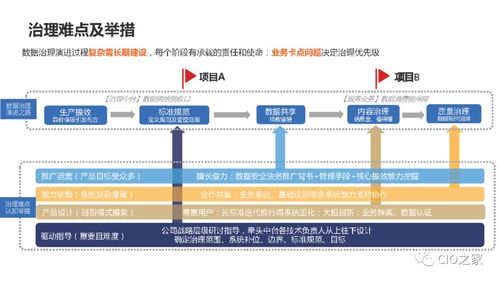
下水務數字化轉型面臨的挑戰不容忽視。其一,數據采集與集成難度大。傳統的下水務系統往往設備老舊,缺乏統一的數據標準,導致信息孤島問題嚴重。其二,資金投入不足。數字化轉型需要大量前期投資,包括硬件升級、軟件開發及人員培訓,而許多水務企業受限于預算,難以全面推進。其三,技術更新與人才短缺。新興技術如物聯網、大數據和人工智能的應用需要專業團隊支持,但行業內缺乏相關技術人才,導致轉型進程緩慢。其四,安全與隱私風險。數字化轉型涉及大量敏感數據,如用戶用水信息和管網監測數據,若管理不當,易引發安全漏洞和隱私泄露。
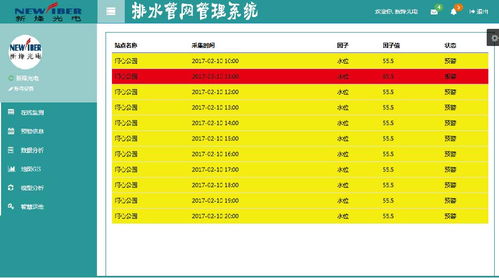
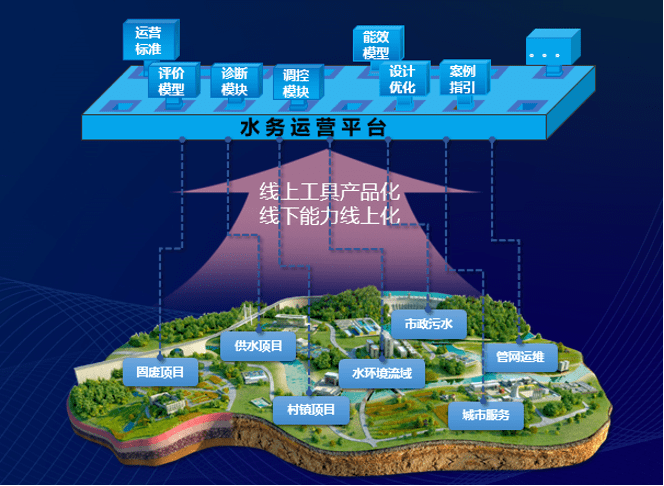
針對這些挑戰,下水務行業已開展多項實踐探索。例如,通過部署智能傳感器和監控設備,實現實時數據采集與傳輸,提升管網監測的精準度。同時,企業積極引入云計算平臺,構建統一的數據管理系統,打破信息壁壘,促進數據共享與分析。在資金方面,部分水務公司采用分步實施策略,先從小規模試點項目入手,逐步擴大應用范圍,以降低風險。與科技公司合作,開發定制化軟件解決方案,如能耗管理系統,幫助優化能源使用,減少運營成本。
能耗管理系統作為數字化轉型的重要組成部分,在能耗監測與管理中發揮著關鍵作用。這類系統通過集成傳感器、數據分析和可視化工具,實時監控水處理過程中的能耗情況,識別高耗能環節,并提供優化建議。例如,在泵站運行中,能耗管理系統可以基于實時數據調整設備運行參數,提高能源利用率,減少碳排放。同時,軟件開發方面,定制化的能耗監測平臺能夠結合水務企業特定需求,提供智能預警和報告功能,助力企業實現可持續運營。行業動態顯示,越來越多的水務企業正積極引入這類系統,以響應綠色發展和節能減碳的號召。
下水務數字化轉型雖面臨諸多挑戰,但通過技術創新和合理實踐,企業能夠逐步克服困難,實現高效、智能的管理。能耗管理系統作為關鍵工具,不僅提升了能耗監測的精度,還推動了行業的可持續發展。未來,隨著技術不斷成熟和人才培養加強,下水務行業有望迎來更廣泛和深度的數字化變革。