近日,好麗友上海工廠成功舉辦開放日活動,向公眾展示了其依托先進軟件開發技術構建的數智化品質保障體系。這一創新舉措不僅彰顯了企業對產品質量與食品安全的高度重視,更為消費者提供了透明化的生產過程視角,讓"舌尖上的安全"真正落到實處。
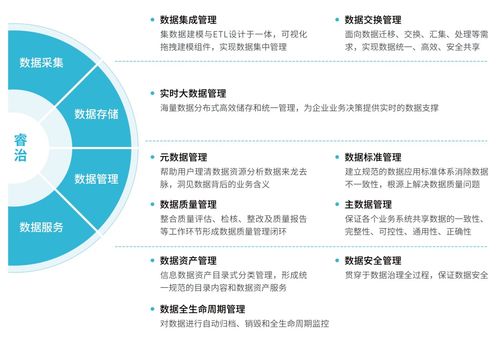
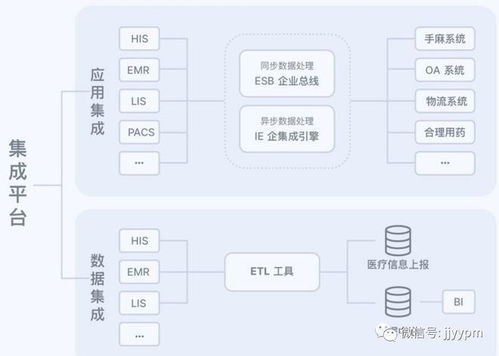
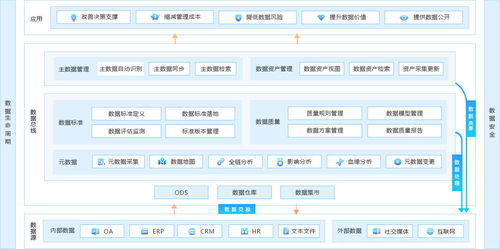
在開放日現場,參觀者通過實地觀摩和互動體驗,深入了解到好麗友如何將軟件開發與食品生產工藝深度融合。從原料入庫到成品出庫,每一個環節都配備了智能監測設備,通過自主研發的食品質量追溯系統實時采集數據,構建起覆蓋全程的數字化品控網絡。
特別值得關注的是,好麗友通過軟件開發實現了三大創新突破:建立了智能預警機制,利用大數據分析技術對生產過程中的關鍵控制點進行24小時監控;開發了移動端質量管理系統,使品控人員能夠隨時隨地掌握生產狀況;構建了消費者可查詢的溯源平臺,只需掃描產品二維碼即可獲取完整的生產流通信息。
工廠負責人表示:"我們投入大量資源進行軟件開發,就是要用科技的力量為食品安全筑起堅實的防線。數智化轉型不僅提升了生產效率,更重要的是建立了更加透明、可信的質量保障體系。"
業內專家認為,好麗友的實踐為食品行業樹立了數字化品質管理的典范。在食品安全日益受到關注的今天,這種將軟件開發與生產管理深度融合的模式,不僅提升了企業自身的質量控制水平,也為整個行業的技術升級提供了可借鑒的經驗。
隨著消費者對食品安全要求的不斷提高,好麗友上海工廠的數智化實踐表明,只有將科技創新與品質管理有機結合,才能真正守護好消費者"舌尖上的安全",贏得市場的持久信任。